 Porównanie NSGA-II i MILP Porównanie NSGA-II i MILP
Porównanie NSGA-II i MILP Porównanie NSGA-II i MILP Decydentem jest planista produkcyjny, odpowiedzialny za organizację harmonogramu produkcji w środowisku warsztatowym (job shop). Przedmiotem decyzji jest ustalenie sekwencji wykonywania operacji dla każdego zadania na dostępnych maszynach, aby zoptymalizować proces produkcyjny.
Wejściem jest chromosom, czyli permutacja określająca kolejność wykonywania operacji dla wszystkich zadań. Każde zadanie składa się z sekwencji operacji, z których każda musi być wykonana na określonej maszynie w zadanym czasie przetwarzania. Zbiór decyzji dopuszczalnych obejmuje wszystkie permutacje spełniające warunki:
Każde zadanie musi być reprezentowane w chromosomie dokładnie tyle razy, ile operacji zawiera.
Operacje dla każdego zadania muszą być wykonywane w ustalonej kolejności.
Każda operacja jest przypisana do jednej maszyny z zadanym czasem przetwarzania.
Wyjściem jest harmonogram określający czasy rozpoczęcia i zakończenia każdej operacji na maszynach. Ocena decyzji opiera się na dwóch funkcjach celu:
Całkowity czas nadgodzin (overtime):
suma czasów przetwarzania operacji, które kończą się po zadanym czasie
dostępności maszyn (capacity_time).
Całkowite opóźnienie (tardiness): suma
opóźnień wszystkich zadań względem ich terminów
(due_dates).
Wyjście jest generowane poprzez dekodowanie chromosomu za pomocą
funkcji decode_schedule, która przypisuje każdej operacji
czas rozpoczęcia i zakończenia, uwzględniając ograniczenia związane z
dostępnością maszyn i kolejnością operacji w zadaniach. Funkcje celu
(nadgodziny i opóźnienie) są obliczane na podstawie harmonogramu, gdzie
każda decyzja (kolejność operacji) wpływa na czasy rozpoczęcia i
zakończenia operacji, a tym samym na wartości funkcji celu.
Celem jest znalezienie zbioru rozwiązań optymalnych w sensie Pareto, które minimalizują jednocześnie całkowity czas nadgodzin i całkowite opóźnienie. Problem jest wielokryterialny, więc nie szukamy jednego optymalnego rozwiązania, lecz zbioru rozwiązań niedominowanych (front Pareto), które zapewniają różne kompromisy między tymi dwoma kryteriami.
Projekt zakłada stworzenie systemu podejmowania decyzji, który automatycznie generuje zbiór rozwiązań Pareto przy użyciu algorytmu NSGA-II. Użytkownik (np. planista) może następnie wybrać jedno z rozwiązań z frontu Pareto, co czyni system również narzędziem wspomagania decyzji. Rola użytkownika polega na analizie wyników (np. wizualizacji harmonogramów w postaci wykresów Gantta, chromosomów lub frontu Pareto) i wyborze rozwiązania najbardziej odpowiedniego dla potrzeb produkcyjnych.
Problem harmonogramowania zadań w środowisku warsztatowym (job shop scheduling) jest klasycznym problemem optymalizacyjnym, szeroko stosowanym w zarządzaniu produkcją, logistyce i planowaniu zasobów. Jego trudność wynika z:
Kombinatorycznej natury problemu (duża liczba możliwych permutacji).
Wielokryterialności (konieczność równoczesnej minimalizacji nadgodzin i opóźnień).
Ograniczeń związanych z sekwencją operacji i dostępnością maszyn.
Znaczenie problemu wynika z jego praktycznego zastosowania w optymalizacji procesów produkcyjnych, gdzie poprawa harmonogramu może prowadzić do redukcji kosztów (nadgodziny) i zwiększenia zadowolenia klientów (przestrzeganie terminów).
Zmienną decyzyjną jest chromosom, czyli wektor \(\mathbf{g} = [g_1, g_2, \ldots, g_L]\), gdzie:
\(L = \sum_{j=0}^{n-1} |J_j|\) to całkowita liczba operacji (dla \(n\) zadań).
\(g_i \in \{0, 1, \ldots, n-1\}\) reprezentuje identyfikator zadania, a każde zadanie \(j\) pojawia się dokładnie \(|J_j|\) razy w chromosomie, gdzie \(|J_j|\) to liczba operacji zadania \(j\).
Chromosom definiuje kolejność przetwarzania operacji, która jest dekodowana do harmonogramu określającego czasy rozpoczęcia i zakończenia każdej operacji.
Problem jest wielokryterialny z dwiema funkcjami celu:
Całkowity czas nadgodzin: \[f_1(\mathbf{g}) = \sum_{o \in S(\mathbf{g})}
\max(0, e_o - \max(c, s_o)),\] gdzie \(S(\mathbf{g})\) to harmonogram wygenerowany
z chromosomu \(\mathbf{g}\), \(s_o\) i \(e_o\) to odpowiednio czasy rozpoczęcia i
zakończenia operacji \(o\), a \(c\) to czas dostępności maszyn
(capacity_time).
Całkowite opóźnienie: \[f_2(\mathbf{g}) = \sum_{j=0}^{n-1} \max(0, C_j -
d_j),\] gdzie \(C_j\) to czas
zakończenia ostatniej operacji zadania \(j\), a \(d_j\) to termin zadania \(j\) (due_dates).
Każda operacja zadania \(j\) musi być wykonana w ustalonej kolejności: dla zadania \(j\), operacja \(o_{j,k}\) musi zakończyć się przed rozpoczęciem \(o_{j,k+1}\), czyli \(e_{j,k} \leq s_{j,k+1}\).
Każda maszyna może przetwarzać tylko jedną operację w danym czasie.
Czasy przetwarzania operacji i przypisania do maszyn są
zdefiniowane w danych wejściowych (lista jobs).
Chromosom musi zawierać dokładnie \(|J_j|\) wystąpień zadania \(j\) dla każdego \(j \in \{0, 1, \ldots, n-1\}\).
Wszystkie operacje muszą być przypisane do maszyn z listy
jobs, a identyfikatory maszyn muszą być z zakresu \(\{0, 1, \ldots, m-1\}\), gdzie \(m\) to liczba maszyn.
Zmienne decyzyjne: Chromosom w postaci permutacji operacji został wybrany, ponieważ jest to standardowe podejście w problemach harmonogramowania warsztatowego. Umożliwia łatwe kodowanie sekwencji operacji i jest kompatybilny z operatorami genetycznymi (np. krzyżowaniem POX i mutacją swap).
Funkcje celu: Minimalizacja nadgodzin i opóźnień odzwierciedla typowe cele w zarządzaniu produkcją: redukcja kosztów operacyjnych (nadgodziny) i zwiększenie punktualności (opóźnienia). Wielokryterialność pozwala na zrównoważenie tych celów.
Ograniczenia: Ograniczenia wynikają z natury problemu warsztatowego, gdzie kolejność operacji i dostępność maszyn są sztywno zdefiniowane. Zapewniają one realistyczne modelowanie środowiska produkcyjnego.
import random
import numpy as np
import matplotlib.pyplot as plt
# Definicja instancji: zadania, maszyny, czasy realizacji i terminy
jobs = [
[(0, 3), (1, 2), (2, 2)], # Zadanie 0: kolejno na maszynie 0(3), 1(2), 2(2)
[(1, 2), (2, 3), (0, 1)], # Zadanie 1: maszyny 1->2->0
[(2, 4), (0, 3), (1, 2)], # Zadanie 2: maszyny 2->0->1
[(0, 2), (2, 1), (1, 4)], # Zadanie 3: maszyny 0->2->1
[(1, 3), (0, 2), (2, 1)] # Zadanie 4: maszyny 1->0->2
]
num_jobs = len(jobs)
due_dates = [8, 7, 10, 6, 9]
capacity_time = 8Opis: Kod importuje biblioteki: random
do losowania, numpy do operacji numerycznych,
matplotlib.pyplot do wizualizacji. Definiuje instancję
problemu: jobs to lista zadań, gdzie każde zadanie to
sekwencja operacji (maszyna, czas przetwarzania); due_dates
to terminy; capacity_time to czas dostępności maszyn.
Opis matematyczny: Dane wejściowe definiują problem harmonogramowania warsztatowego. Niech:
\(J = \{0, 1, \ldots, n-1\}\) to zbiór \(n\) zadań, gdzie \(n = \texttt{num\_jobs} = 5\).
\(M = \{0, 1, \ldots, m-1\}\) to zbiór \(m=3\) maszyn.
Dla zadania \(j \in J\), \(O_j = \{(m_{j,k}, p_{j,k})\}_{k=0}^{|O_j|-1}\) to sekwencja operacji, gdzie \(m_{j,k} \in M\) to maszyna, a \(p_{j,k} > 0\) to czas przetwarzania (np. dla zadania 0: \(O_0 = \{(0,3), (1,2), (2,2)\}\)).
\(d_j \in \mathbb{R}^+\) to
termin zadania \(j\), zapisany w
due_dates (np. \(d_0 =
8\)).
\(c \in \mathbb{R}^+\) to czas
dostępności maszyn, capacity_time = 8.
def decode_schedule(gene):
next_op = [0] * num_jobs
job_end = [0] * num_jobs
machine_end = {m: 0 for m in range(3)}
schedule = []
for job_id in gene:
op_idx = next_op[job_id]
if op_idx >= len(jobs[job_id]):
continue
machine, proc_time = jobs[job_id][op_idx]
start = max(job_end[job_id], machine_end[machine])
end = start + proc_time
schedule.append((job_id, op_idx, machine, start, end))
job_end[job_id] = end
machine_end[machine] = end
next_op[job_id] += 1
total_tardiness = sum(max(0, job_end[j] - due_dates[j]) for j in range(num_jobs))
total_overtime = sum(max(0, end - max(capacity_time, start)) for _, _, _, start, end in schedule)
return total_overtime, total_tardiness, scheduleOpis: Funkcja decode_schedule
przekształca chromosom \(\mathbf{g}\)
na harmonogram \(S(\mathbf{g})\). Dla
każdego \(g_i \in \mathbf{g}\)
przypisuje operację zadania \(j = g_i\)
do maszyny, obliczając czas rozpoczęcia \(s_o
= \max(C_j, M_m)\) (gdzie \(C_j\) to czas zakończenia zadania \(j\), \(M_m\) to czas zakończenia maszyny \(m\)) i czas zakończenia \(e_o = s_o + p_{j,k}\). Oblicza \(f_1(\mathbf{g})\) i \(f_2(\mathbf{g})\) zgodnie z podanymi
wzorami.
Opis matematyczny: Chromosom \(\mathbf{g} = [g_1, g_2, \ldots, g_L]\), gdzie \(L = \sum_{j \in J} |O_j| = 15\), koduje kolejność operacji. Funkcja dekoduje \(\mathbf{g}\) na harmonogram \(S(\mathbf{g}) = \{(j, k, m_{j,k}, s_{j,k}, e_{j,k})\}\), gdzie:
\(j = g_i\) to zadanie, \(k = \texttt{next\_op[j]}\) to indeks operacji w \(O_j\).
\(s_{j,k} = \max(C_j, M_{m_{j,k}})\), gdzie \(C_j = \texttt{job\_end[j]}\) to czas zakończenia ostatniej operacji zadania \(j\), a \(M_m = \texttt{machine\_end[m]}\) to czas zakończenia ostatniej operacji na maszynie \(m\).
\(e_{j,k} = s_{j,k} + p_{j,k}\), gdzie \(p_{j,k}\) to czas przetwarzania operacji.
Funkcje celu obliczane są jako: \[f_1(\mathbf{g}) = \sum_{(j,k,m,s,e) \in S(\mathbf{g})} \max(0, e - \max(c, s)),\] \[f_2(\mathbf{g}) = \sum_{j \in J} \max(0, C_j - d_j).\]
def pox_crossover(parent1, parent2):
length = len(parent1)
chosen_job = random.choice(list(set(parent1)))
child1 = [-1] * length
child2 = [-1] * length
for i in range(length):
if parent1[i] == chosen_job:
child1[i] = chosen_job
if parent2[i] == chosen_job:
child2[i] = chosen_job
rem1 = [j for j in parent2 if j != chosen_job]
rem2 = [j for j in parent1 if j != chosen_job]
p1 = p2 = 0
for i in range(length):
if child1[i] == -1:
child1[i] = rem1[p1]
p1 += 1
if child2[i] == -1:
child2[i] = rem2[p2]
p2 += 1
return child1, child2Opis: Funkcja pox_crossover
implementuje krzyżowanie POX, które zachowuje kolejność operacji
wybranego zadania \(j\) z jednego
rodzica w potomku, a pozostałe pozycje wypełnia zadaniami z drugiego
rodzica. Gwarantuje poprawność chromosomów potomnych.
Opis matematyczny: Dla rodziców \(\mathbf{g}^1, \mathbf{g}^2 \in \mathbb{Z}^L\), krzyżowanie POX generuje potomków \(\mathbf{c}^1, \mathbf{c}^2\). Algorytm:
Wybiera losowe zadanie \(j^* \in J\) (np. \(j^* = \texttt{chosen\_job}\)).
Kopiuje pozycje zadania \(j^*\) z \(\mathbf{g}^1\) do \(\mathbf{c}^1\) i z \(\mathbf{g}^2\) do \(\mathbf{c}^2\): \[c^1_i = g^1_i \text{ jeśli } g^1_i = j^*, \quad c^2_i = g^2_i \text{ jeśli } g^2_i = j^*,\] w przeciwnym razie \(c^1_i = c^2_i = -1\).
Pozostałe pozycje w \(\mathbf{c}^1\) wypełnia zadaniami z \(\mathbf{g}^2 \setminus \{j^*\}\) w ich kolejności, a w \(\mathbf{c}^2\) z \(\mathbf{g}^1 \setminus \{j^*\}\).
Wynik spełnia ograniczenie: \(| \{i : c^1_i = j\} | = | \{i : c^2_i = j\} | = |O_j|\) dla każdego \(j \in J\).
def mutate_swap(gene, prob=1.0):
if random.random() < prob:
a, b = random.sample(range(len(gene)), 2)
gene[a], gene[b] = gene[b], gene[a]
return geneOpis: Funkcja mutate_swap wykonuje
losową zamianę dwóch pozycji w chromosomie z prawdopodobieństwem
prob, zapewniając, że chromosom pozostaje ważny.
Opis matematyczny: Dla chromosomu \(\mathbf{g} \in \mathbb{Z}^L\), mutacja
swap z prawdopodobieństwem prob losowo wybiera
indeksy \(a, b \in \{0, 1, \ldots,
L-1\}\), \(a \neq b\), i
zamienia wartości: \[\mathbf{g}'_i =
\begin{cases}
g_b & \text{jeśli } i = a, \\
g_a & \text{jeśli } i = b, \\
g_i & \text{w przeciwnym razie}.
\end{cases}\] Zamiana nie zmienia liczby wystąpień każdego
zadania, więc \(\mathbf{g}'\)
spełnia ograniczenie: \[|\{i : g'_i =
j\}| = |O_j|, \quad \forall j \in J.\]
def local_search(gene, eval_func, trials=3):
best_gene = gene.copy()
best_obj = eval_func(best_gene)[:2]
for _ in range(trials):
i, j = random.sample(range(len(best_gene)), 2)
new_gene = best_gene.copy()
new_gene[i], new_gene[j] = new_gene[j], new_gene[i]
new_obj = eval_func(new_gene)[:2]
if ((new_obj[0] <= best_obj[0] and new_obj[1] <= best_obj[1]) and
(new_obj[0] < best_obj[0] or new_obj[1] < best_obj[1])):
best_gene, best_obj = new_gene, new_obj
return best_gene, best_objOpis: Funkcja local_search ulepsza
chromosom poprzez trials losowych zamian, akceptując nowe
rozwiązanie, jeśli poprawia przynajmniej jedną funkcję celu bez
pogarszania drugiej.
Opis matematyczny: Funkcja wykonuje lokalne
przeszukiwanie w przestrzeni chromosomów. Dla chromosomu \(\mathbf{g}\), w każdym z
trials losuje \(i, j \in \{0, 1,
\ldots, L-1\}\), \(i \neq j\), i
tworzy \(\mathbf{g}'\) przez
zamianę \(g_i\) i \(g_j\). Ocenia \(\mathbf{f}(\mathbf{g}') =
(f_1(\mathbf{g}'), f_2(\mathbf{g}'))\) za pomocą
eval_func i aktualizuje \(\mathbf{g}\) na \(\mathbf{g}'\), jeśli: \[f_1(\mathbf{g}') \leq f_1(\mathbf{g}) \land
f_2(\mathbf{g}') \leq f_2(\mathbf{g}) \land (f_1(\mathbf{g}')
< f_1(\mathbf{g}) \lor f_2(\mathbf{g}') <
f_2(\mathbf{g})).\] Zwraca najlepszy chromosom \(\mathbf{g}^*\) i jego wartości celu \(\mathbf{f}(\mathbf{g}^*)\).
def nondominated_sort(pop):
N = len(pop)
dominated_count = [0] * N
dom_list = [[] for _ in range(N)]
fronts = [[]]
for p in range(N):
for q in range(N):
if p == q: continue
vp = pop[p]['obj']; vq = pop[q]['obj']
if (vp[0] <= vq[0] and vp[1] <= vq[1]) and (vp[0] < vq[0] or vp[1] < vq[1]):
dom_list[p].append(q)
elif (vq[0] <= vp[0] and vq[1] <= vp[1]) and (vq[0] < vp[0] or vq[1] < vp[1]):
dominated_count[p] += 1
if dominated_count[p] == 0:
fronts[0].append(p)
i = 0
while fronts[i]:
next_front = []
for p in fronts[i]:
for q in dom_list[p]:
dominated_count[q] -= 1
if dominated_count[q] == 0:
next_front.append(q)
i += 1
fronts.append(next_front)
fronts.pop()
return frontsOpis matematyczny: Funkcja
nondominated_sort implementuje sortowanie niedominowane,
kluczowe dla NSGA-II. Dla populacji \(P =
\{\mathbf{g}_1, \mathbf{g}_2, \ldots, \mathbf{g}_N\}\) generuje
fronty Pareto \(\mathcal{F}_1, \mathcal{F}_2,
\ldots\), gdzie \(\mathcal{F}_1\) zawiera rozwiązania
niedominowane. Algorytm:
Dla każdego \(\mathbf{g}_p \in
P\) z \(\mathbf{f}(\mathbf{g}_p) =
(f_1(\mathbf{g}_p), f_2(\mathbf{g}_p))\), porównuje z każdym
\(\mathbf{g}_q \in P\), \(p \neq q\). \(\mathbf{g}_p\) dominuje \(\mathbf{g}_q\), jeśli: \[f_1(\mathbf{g}_p) \leq f_1(\mathbf{g}_q) \land
f_2(\mathbf{g}_p) \leq f_2(\mathbf{g}_q) \land (f_1(\mathbf{g}_p) <
f_1(\mathbf{g}_q) \lor f_2(\mathbf{g}_p) <
f_2(\mathbf{g}_q)).\] Jeśli tak, \(q\) dodawany jest do
dom_list[p]. Jeśli \(\mathbf{g}_q\) dominuje \(\mathbf{g}_p\), zwiększa się
dominated_count[p].
\(\mathbf{g}_p\) z
dominated_count[p] = 0 trafia do \(\mathcal{F}_1\).
Dla każdego \(\mathbf{g}_p \in
\mathcal{F}_i\), zmniejsza dominated_count[q] dla
\(q \in \texttt{dom\_list[p]}\). Jeśli
dominated_count[q] = 0, wtedy \(q\) trafia do \(\mathcal{F}_{i+1}\).
Proces trwa, aż \(\bigcup_i \mathcal{F}_i = P\).
Zwraca fronty \(\mathcal{F}_i\), gdzie \(\mathcal{F}_1\) to front Pareto.
def crowding_distance(front, pop):
distance = {i: 0.0 for i in front}
if len(front) <= 2:
for i in front:
distance[i] = float('inf')
return distance
front_sorted0 = sorted(front, key=lambda i: pop[i]['obj'][0])
front_sorted1 = sorted(front, key=lambda i: pop[i]['obj'][1])
distance[front_sorted0[0]] = float('inf')
distance[front_sorted0[-1]] = float('inf')
distance[front_sorted1[0]] = float('inf')
distance[front_sorted1[-1]] = float('inf')
f0_min = pop[front_sorted0[0]]['obj'][0]
f0_max = pop[front_sorted0[-1]]['obj'][0]
f1_min = pop[front_sorted1[0]]['obj'][1]
f1_max = pop[front_sorted1[-1]]['obj'][1]
for k in range(1, len(front)-1):
i = front_sorted0[k]
distance[i] += (pop[front_sorted0[k+1]]['obj'][0] - pop[front_sorted0[k-1]]['obj'][0]) / (f0_max - f0_min if f0_max != f0_min else 1)
i = front_sorted1[k]
distance[i] += (pop[front_sorted1[k+1]]['obj'][1] - pop[front_sorted1[k-1]]['obj'][1]) / (f1_max - f1_min if f1_max != f1_min else 1)
return distanceOpis matematyczny: Funkcja
crowding_distance oblicza odległość tłumu dla osobników w
froncie \(\mathcal{F}_i\), promując
różnorodność. Dla \(\mathbf{g}_p \in
\mathcal{F}_i\), odległość \(d_p\) to: \[d_p
= \sum_{k=1}^2 \frac{f_k(\mathbf{g}_{p+1}^k) -
f_k(\mathbf{g}_{p-1}^k)}{f_k^{\max} - f_k^{\min}},\] gdzie \(\mathbf{g}_{p+1}^k, \mathbf{g}_{p-1}^k\) to
sąsiedzi \(\mathbf{g}_p\) w liście
posortowanej według \(f_k\), a \(f_k^{\max}, f_k^{\min}\) to maksymalna i
minimalna wartość \(f_k\) w \(\mathcal{F}_i\). Dla skrajnych osobników
\(d_p = \infty\). Jeśli \(|\mathcal{F}_i| \leq 2\), \(d_p = \infty\) dla wszystkich \(p\).
def tournament_select(pop):
i, j = random.sample(range(len(pop)), 2)
if pop[i]['rank'] < pop[j]['rank']:
return i
if pop[i]['rank'] > pop[j]['rank']:
return j
if pop[i]['crowding'] > pop[j]['crowding']:
return i
if pop[i]['crowding'] < pop[j]['crowding']:
return j
return random.choice([i, j])Opis matematyczny: Funkcja wybiera osobnika z \(P\) przez turniej dwóch losowych \(\mathbf{g}_i, \mathbf{g}_j\). Kryteria wyboru:
Jeśli \(\text{rank}_i < \text{rank}_j\) (niższy front Pareto), wybiera \(i\).
Jeśli \(\text{rank}_i = \text{rank}_j\) i \(d_i > d_j\) (większa odległość tłumu), wybiera \(i\).
W razie remisu losuje \(i\) lub \(j\).
Matematycznie, wybór to: \[\text{argmin}_{p \in \{i,j\}} (\text{rank}_p, -d_p),\] gdzie niższy \(\text{rank}\) ma priorytet, a wyższy \(d_p\) jest drugorzędny.
def plot_pareto(population, gen):
fig, ax = plt.subplots(figsize=(8, 6))
for sol in population:
ax.scatter(sol['obj'][0], sol['obj'][1], c='blue', alpha=0.5)
ax.set_xlabel('Nadgodziny (Overtime)')
ax.set_ylabel('Opóźnienia (Tardiness)')
ax.set_title(f'Front Pareto - Generacja {gen}')
plt.grid(True)
plt.show()
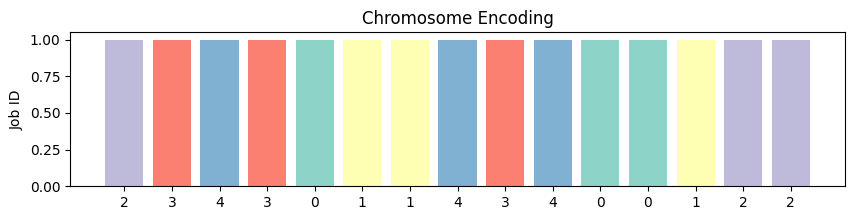
def plot_chromosome(chromosome):
fig, ax = plt.subplots(figsize=(10, 2))
for i, job_id in enumerate(chromosome):
ax.bar(i, 1, color=plt.cm.Set3(job_id % 12))
ax.set_title('Chromosome Encoding')
ax.set_ylabel('Job ID')
ax.set_xticks(range(len(chromosome)))
ax.set_xticklabels(chromosome)
plt.show()
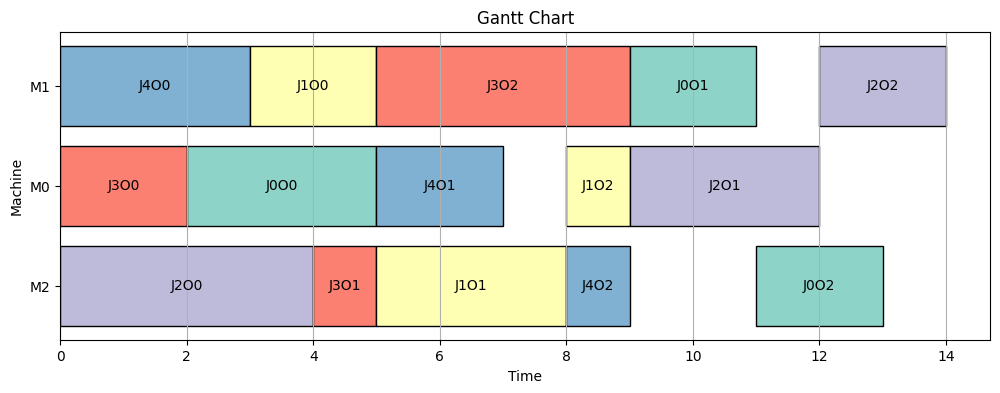
def plot_gantt_chart(schedule):
fig, ax = plt.subplots(figsize=(12, 4))
machines = {0: 'M0', 1: 'M1', 2: 'M2'}
for job_id, op_idx, machine, start, end in schedule:
ax.barh(machines[machine], end - start, left=start, color=plt.cm.Set3(job_id % 12), edgecolor='black')
ax.text((start + end) / 2, machines[machine], f'J{job_id}O{op_idx}', ha='center', va='center')
ax.set_xlabel('Time')
ax.set_ylabel('Machine')
ax.set_yticks(list(machines.values()))
ax.set_title('Gantt Chart')
plt.grid(True, axis='x')
plt.show()Opis matematyczny: Funkcje wizualizują wyniki:
plot_pareto: Rysuje zbiór \(\{(f_1(\mathbf{g}), f_2(\mathbf{g})) \mid
\mathbf{g} \in P\}\) jako punkty na płaszczyźnie \((f_1, f_2)\) dla każdej generacji, z
tytułem wskazującym numer generacji.
plot_chromosome: Wizualizuje \(\mathbf{g} = [g_1, \ldots, g_L]\) jako
histogram, gdzie \(g_i\) to
identyfikator zadania na pozycji \(i\),
z kolorami z palety Set3.
plot_gantt_chart: Tworzy wykres Gantta dla \(S(\mathbf{g}) = \{(j, k, m, s, e)\}\),
gdzie prostokąt na osi maszyny \(m\) od
\(s\) do \(e\) reprezentuje operację \((j,k)\), oznaczoną etykietą
JjOk.
def run_nsga(pop_size=40, gens=80, cx_prob=0.9, mut_prob=0.2):
base_gene = []
for j in range(num_jobs):
base_gene += [j] * len(jobs[j])
population = []
for _ in range(pop_size):
gene = base_gene.copy()
random.shuffle(gene)
ot, tard, _ = decode_schedule(gene)
population.append({'gene': gene, 'obj': (ot, tard)})
for gen in range(gens):
print(f"\nGeneracja {gen+1}/{gens}")
print(f"Rozmiar populacji: {pop_size}")
print(f"Prawdopodobieństwo krzyżowania: {cx_prob}")
print(f"Prawdopodobieństwo mutacji: {mut_prob}")
fronts = nondominated_sort(population)
for rank_idx, front in enumerate(fronts):
for idx in front:
population[idx]['rank'] = rank_idx
dist = crowding_distance(front, population)
for idx in front:
population[idx]['crowding'] = dist[idx]
# Pareto front statistics
pareto_front = [population[i] for i in fronts[0]]
pareto_objs = [(sol['obj'][0], sol['obj'][1]) for sol in pareto_front]
print("Front Pareto (nadgodziny, opóźnienia):", pareto_objs)
min_overtime = min(sol['obj'][0] for sol in pareto_front)
min_tardiness = min(sol['obj'][1] for sol in pareto_front)
print(f"Najmniejsze nadgodziny: {min_overtime}")
print(f"Najmniejsze opóźnienia: {min_tardiness}")
# Select a representative solution from Pareto front (min sum of objectives)
best_pareto_sol = min(pareto_front, key=lambda x: x['obj'][0] + x['obj'][1])
best_gene = best_pareto_sol['gene']
ot, tard, schedule = decode_schedule(best_gene)
print(f"Chromosom dla generacji {gen+1}: {best_gene}")
print(f"Nadgodziny: {ot}, Opóźnienia: {tard}")
# Visualize chromosome and Gantt chart for the selected solution
print(f"Wizualizacja chromosomu dla generacji {gen+1}")
plot_chromosome(best_gene)
print(f"Wykres Gantta dla generacji {gen+1}")
plot_gantt_chart(schedule)
# Existing Pareto front visualization
plot_pareto(population, gen+1)
offspring = []
while len(offspring) < pop_size:
i = tournament_select(population)
j = tournament_select(population)
parent1 = population[i]['gene']
parent2 = population[j]['gene']
if random.random() < cx_prob:
child1, child2 = pox_crossover(parent1, parent2)
else:
child1, child2 = parent1.copy(), parent2.copy()
child1 = mutate_swap(child1, mut_prob)
child2 = mutate_swap(child2, mut_prob)
child1, _ = local_search(child1, decode_schedule, trials=3)
child2, _ = local_search(child2, decode_schedule, trials=3)
ot1, tard1, _ = decode_schedule(child1)
ot2, tard2, _ = decode_schedule(child2)
offspring.append({'gene': child1, 'obj': (ot1, tard1)})
if len(offspring) < pop_size:
offspring.append({'gene': child2, 'obj': (ot2, tard2)})
combined = population + offspring
new_pop = []
fronts = nondominated_sort(combined)
for front in fronts:
if len(new_pop) + len(front) <= pop_size:
dist = crowding_distance(front, combined)
for idx in front:
combined[idx]['crowding'] = dist[idx]
new_pop.append(combined[idx])
else:
dist = crowding_distance(front, combined)
sorted_front = sorted(front, key=lambda x: dist[x], reverse=True)
needed = pop_size - len(new_pop)
for idx in sorted_front[:needed]:
new_pop.append(combined[idx])
break
population = new_pop
fronts = nondominated_sort(population)
pareto = [population[i] for i in fronts[0]]
return paretoOpis matematyczny: Funkcja implementuje NSGA-II
przez gens generacji:
Inicjalizuje \(P_0\) jako zbiór
pop_size losowych permutacji wektora bazowego \(\mathbf{b} = [0^{|O_0|}, 1^{|O_1|}, \ldots,
(n-1)^{|O_{n-1}|}]\), gdzie \(|O_j| =
3\).
Dla generacji \(t = 1, \ldots, \texttt{gens}\):
Generuje fronty Pareto \(\mathcal{F}_i\) za pomocą
nondominated_sort.
Przypisuje rangi \(\text{rank}_p\) i odległości tłumu \(d_p\) za pomocą
crowding_distance.
Wyświetla statystyki frontu Pareto \(\mathcal{F}_1\) i wybiera najlepsze rozwiązanie \(\mathbf{g}^* = \text{argmin}_{\mathbf{g} \in \mathcal{F}_1} (f_1(\mathbf{g}) + f_2(\mathbf{g}))\).
Wizualizuje \(\mathbf{g}^*\) jako chromosom i harmonogram \(S(\mathbf{g}^*)\) jako wykres Gantta, oraz \(\{(f_1(\mathbf{g}), f_2(\mathbf{g})) \mid \mathbf{g} \in P\}\) jako front Pareto.
Generuje populację potomną \(Q_t\) przez tournament_select,
pox_crossover, mutate_swap i
local_search.
Tworzy \(R_t = P_t \cup Q_t\) i wybiera \(P_{t+1}\) przez elitarny wybór.
Zwraca finalny front Pareto \(\mathcal{F}_1\).
pareto_solutions = run_nsga(pop_size=40, gens=80, cx_prob=0.9, mut_prob=0.2)
pareto_objs = sorted({(sol['obj'][0], sol['obj'][1]) for sol in pareto_solutions})
print("\nOstateczny front Pareto (nadgodziny, opóźnienia):", pareto_objs)
best_gene = pareto_solutions[0]['gene']
ot, tard, schedule = decode_schedule(best_gene)
print(f"Najlepszy chromosom: {best_gene}")
print(f"Nadgodziny: {ot}")
print(f"Opóźnienia: {tard}")
# Wizualizacja najlepszego rozwiązania
plot_chromosome(best_gene)
plot_gantt_chart(schedule)Opis matematyczny: Kod uruchamia
run_nsga z parametrami: pop_size = 40,
gens = 80, cx_prob = 0.9,
mut_prob = 0.2. Zwraca \(\mathcal{F}_1\), wyświetla zbiór \(\{(f_1(\mathbf{g}), f_2(\mathbf{g})) \mid
\mathbf{g} \in \mathcal{F}_1\}\), wybiera \(\mathbf{g}^*\) jako pierwsze rozwiązanie z
\(\mathcal{F}_1\), oraz wizualizuje
\(\mathbf{g}^*\) i \(S(\mathbf{g}^*)\).
Ostateczny front Pareto (nadgodziny, opóźnienia): \([(11, 15), (12, 14)]\).
Najlepszy chromosom: \([2, 3, 4, 3, 0, 1, 1, 4, 3, 4, 0, 0, 1, 2, 2]\).
Nadgodziny: 12.
Opóźnienia: 14.
MILP (Mixed Integer Linear Programming) to metoda optymalizacji, w której funkcja celu i ograniczenia są liniowe, a niektóre zmienne decyzyjne są całkowitoliczbowe (tutaj binarne). W problemie harmonogramowania zadań w środowisku warsztatowym MILP pozwala na precyzyjne modelowanie sekwencji operacji, czasów rozpoczęcia i zakończenia oraz konfliktów między operacjami na maszynach.
| Element | Opis | Sformułowanie matematyczne |
|---|---|---|
| Zmienne ciągłe | Czasy rozpoczęcia operacji, maksymalne czasy zakończenia na maszynach, nadgodziny, opóźnienia zadań. | \(s_{j,k} \geq 0\), \(C_m \geq 0\), \(O_m \geq 0\), \(T_j \geq 0\) |
| Zmienne binarne | Określają kolejność operacji na tej samej maszynie. | \(y_{j,k,i,l} \in \{0, 1\}\) |
| Funkcja celu | Minimalizacja lexicograficzna sumy nadgodzin i sumy opóźnień. | \(\text{minimize } \left( \sum_{m \in M} O_m, \sum_{j \in J} T_j \right)\) |
| Ograniczenia liniowe | Zapewniają technologiczną kolejność operacji, brak nakładania się operacji na maszynach, obliczanie opóźnień i nadgodzin. | Patrz sekcja matematycznego opisu modelu |
MILP jest odpowiedni dla tego problemu, ponieważ pozwala na precyzyjne sformułowanie ograniczeń harmonogramowania, takich jak sekwencyjność operacji i wyłączność maszyn. Jednak dla dużych instancji problem może stać się obliczeniowo kosztowny z powodu kombinatorycznej natury zmiennych binarnych.
Poniżej przedstawiono kod w języku OPL użyty do rozwiązania problemu w CPLEX:
range J = 0..4; // zadania
range K = 1..3; // operacje w zadaniu
range M = 0..2; // maszyny
int machine[J][K] = // przypisanie operacji do maszyn
[[0,1,2],
[1,2,0],
[2,0,1],
[0,2,1],
[1,0,2]];
int p[J][K] = // czasy realizacji operacji
[[3,2,2],
[2,3,1],
[4,3,2],
[2,1,4],
[3,2,1]];
int due[J] = [8, 7, 10, 6, 9]; // terminy zakończenia zadań
int cap = 8;
int bigM = 100;
// === Zmienne decyzyjne ===
dvar float+ start[J][K]; // (zadanie, krok)
dvar boolean Y[J][K][J][K]; // kolejność operacji
dvar float+ Cmax[M]; // maks. czas zakończenia
dvar float+ Overtime[M]; // nadgodziny
dvar float+ T[J]; // opóźnienie
// === Wyrażenia celu ===
dexpr float sumOver = sum(m in M) Overtime[m];
dexpr float sumTard = sum(j in J) T[j];
// === Funkcja celu ===
minimize staticLex(sumOver, sumTard);
// === Ograniczenia ===
subject to {
// 1. Kolejność operacji w zadaniu (technologiczna)
forall(j in J, k in 2..3)
start[j][k] >= start[j][k-1] + p[j][k-1];
// 2. Brak nakładania operacji na tej samej maszynie
forall(j in J, k in K, i in J, l in K:
(j < i || (j == i && k < l)) &&
machine[j][k] == machine[i][l]) {
start[j][k] + p[j][k] <= start[i][l] + bigM * (1 - Y[j][k][i][l]);
start[i][l] + p[i][l] <= start[j][k] + bigM * Y[j][k][i][l];
Y[j][k][i][l] + Y[i][l][j][k] == 1;
}
// 3. Opóźnienie: T[j] >= zakończenie ostatniej operacji - termin
forall(j in J)
T[j] >= start[j][3] + p[j][3] - due[j];
// 4. Cmax i nadgodziny
forall(m in M, j in J, k in K: machine[j][k] == m)
Cmax[m] >= start[j][k] + p[j][k];
forall(m in M)
Overtime[m] >= Cmax[m] - cap;
}Opis kodu:
Dane wejściowe: Definiują instancję problemu:
\(J = \{0, 1, \ldots, 4\}\): 5 zadań.
\(K = \{1, 2, 3\}\): 3 operacje na zadanie.
\(M = \{0, 1, 2\}\): 3 maszyny.
\(\text{machine}[j][k]\): Maszyna dla operacji \(k\) zadania \(j\).
\(p[j][k]\): Czas przetwarzania operacji \(k\) zadania \(j\).
\(\text{due}[j]\): Termin zadania \(j\).
\(\text{cap} = 8\): Czas dostępności maszyn bez nadgodzin.
\(\text{bigM} = 100\): Duża liczba do liniowego modelowania ograniczeń.
Zmienne decyzyjne: Określają harmonogram i decyzje:
\(\text{start}[j][k]\): Czas rozpoczęcia operacji.
\(Y[j][k][i][l]\): Zmienna binarna określająca, czy operacja \((j,k)\) poprzedza \((i,l)\) na tej samej maszynie.
\(C_{\text{max}}[m]\): Maksymalny czas zakończenia na maszynie \(m\).
\(\text{Overtime}[m]\): Nadgodziny na maszynie \(m\).
\(T[j]\): Opóźnienie zadania \(j\).
Funkcja celu i ograniczenia: Zdefiniowane w poniższej tabeli.
| Element | Opis | Sformułowanie w OPL |
|---|---|---|
| Funkcja celu | Minimalizacja lexicograficzna: najpierw suma nadgodzin, potem suma opóźnień. | minimize staticLex(sumOver, sumTard) |
| Ograniczenie 1: Kolejność operacji | Każda operacja \(k\) zadania \(j\) zaczyna się po zakończeniu poprzedniej operacji \(k-1\). | forall(j in J, k in 2..3) start[j][k] >= start[j][k-1] + p[j][k-1]; |
| Ograniczenie 2: Brak nakładania | Operacje na tej samej maszynie nie mogą się nakładać; zmienna binarna \(Y\) określa kolejność. | forall(j in J, k in K, i in J, l in K: (j < i || (j == i && k < l)) && machine[j][k] == machine[i][l]) { ... } |
| Ograniczenie 3: Opóźnienie | Opóźnienie zadania \(j\) to nadmiar czasu zakończenia ostatniej operacji nad termin. | forall(j in J) T[j] >= start[j][3] + p[j][3] - due[j]; |
| Ograniczenie 4: Nadgodziny | Nadgodziny na maszynie \(m\) to czas zakończenia operacji przekraczający limit \(c\). | forall(m in M, j in J, k in K: machine[j][k] == m) Cmax[m] >= start[j][k] + p[j][k];
forall(m in M) Overtime[m] >= Cmax[m] - cap; |
Wynik CPLEX: Rozwiązanie daje:
Suma nadgodzin: 11 (\(\text{Overtime} = [3, 5, 3]\)).
Suma opóźnień: 15 (\(T = [3, 4, 3, 5, 0]\)).
Czasy rozpoczęcia operacji (\(\text{start}\)) określają harmonogram.
\(C_{\text{max}} = [11, 13, 11]\): maksymalne czasy zakończenia na maszynach.
Niech: - \(J = \{0, 1, \ldots, 4\}\): zbiór zadań. - \(K = \{1, 2, 3\}\): zbiór operacji dla każdego zadania. - \(M = \{0, 1, 2\}\): zbiór maszyn. - \(m_{j,k} \in M\): maszyna dla operacji \(k\) zadania \(j\). - \(p_{j,k} > 0\): czas przetwarzania operacji \(k\) zadania \(j\). - \(d_j > 0\): termin zadania \(j\). - \(c = 8\): czas dostępności maszyn.
Zmienne decyzyjne:
\(s_{j,k} \geq 0\): czas rozpoczęcia operacji \(k\) zadania \(j\).
\(y_{j,k,i,l} \in \{0, 1\}\): \(y_{j,k,i,l} = 1\), jeśli operacja \((j,k)\) poprzedza \((i,l)\) na maszynie \(m_{j,k} = m_{i,l}\).
\(C_m \geq 0\): maksymalny czas zakończenia na maszynie \(m\).
\(O_m \geq 0\): nadgodziny na maszynie \(m\).
\(T_j \geq 0\): opóźnienie zadania \(j\).
Funkcja celu: \[\text{minimize } \left( \sum_{m \in M} O_m, \sum_{j \in J} T_j \right),\] gdzie minimalizacja jest lexicograficzna (najpierw nadgodziny, potem opóźnienia).
Ograniczenia:
Kolejność operacji w zadaniu: \[s_{j,k} \geq s_{j,k-1} + p_{j,k-1}, \quad \forall j \in J, k \in \{2, 3\}.\]
Brak nakładania na maszynach: Dla wszystkich \(j, i \in J\), \(k, l \in K\), takich że \(m_{j,k} = m_{i,l}\) i \((j < i) \lor (j = i \land k < l)\): \[s_{j,k} + p_{j,k} \leq s_{i,l} + M (1 - y_{j,k,i,l}),\] \[s_{i,l} + p_{i,l} \leq s_{j,k} + M y_{j,k,i,l},\] \[y_{j,k,i,l} + y_{i,l,j,k} = 1,\] gdzie \(M = 100\) to duża liczba.
Opóźnienie zadania: \[T_j \geq s_{j,3} + p_{j,3} - d_j, \quad \forall j \in J.\]
Maksymalny czas na maszynie: \[C_m \geq s_{j,k} + p_{j,k}, \quad \forall m \in M, j \in J, k \in K : m_{j,k} = m.\]
Nadgodziny: \[O_m \geq C_m - c, \quad \forall m \in M.\]
Interpretacja matematyczna: Model MILP zapewnia, że harmonogram respektuje technologiczne ograniczenia (kolejność operacji), zasoby (jedna operacja na maszynie w danym czasie) oraz minimalizuje nadgodziny i opóźnienia. Zmienne binarne \(y_{j,k,i,l}\) liniowo modelują decyzje o kolejności, co pozwala CPLEX na efektywne rozwiązanie problemu metodą branch-and-bound.
Wyniki harmonogramowania przedstawiono na podstawie danych
wejściowych, w tym macierzy czasów rozpoczęcia zadań
(start), czasów przetwarzania (p), macierzy
przypisania maszyn (Y) oraz wartości Cmax i
Overtime. Kluczowe rezultaty obejmują:
Czas zakończenia (Cmax): Maksymalne
czasy zakończenia na maszynach wynoszą \(C_{\text{max}} = [11, 13, 11]\). Oznacza
to, że maszyny 0 i 2 kończą pracę w czasie 11, a maszyna 1 w czasie
13.
Nadgodziny (Overtime): Wartości
nadgodzin dla maszyn wynoszą \([3, 5,
3]\), co wskazuje na dodatkowe obciążenie czasowe dla każdej
maszyny.
Czasy rozpoczęcia zadań: Macierz
start określa czasy rozpoczęcia dla każdego zadania na
każdej maszynie.
Poniższy wykres Gantta przedstawia harmonogram zadań dla pięciu zadań
na trzech maszynach. Każde zadanie jest reprezentowane przez prostokąt,
którego początek odpowiada czasowi rozpoczęcia (start), a
długość odpowiada czasowi przetwarzania (p) na podstawie
przypisania maszyn w macierzy machine.
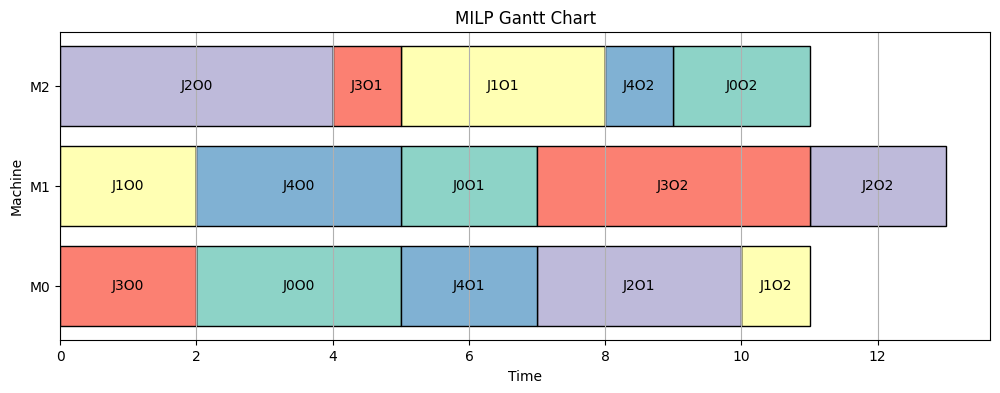
Wykres Gantta pokazuje, że zadania są efektywnie przypisane do
maszyn, z uwzględnieniem czasów rozpoczęcia i przetwarzania. Zadanie 2
wymaga najdłuższego czasu zakończenia (9 jednostek), co jest zgodne z
wartością Cmax. Nadgodziny na maszynach wskazują na
możliwość dalszej optymalizacji obciążenia.
Algorytm NSGA-II i model MILP w CPLEX rozwiązują ten sam problem harmonogramowania zadań w środowisku warsztatowym, minimalizując dwie funkcje celu: całkowity czas nadgodzin (overtime) i całkowite opóźnienie (tardiness). Jednak różnią się podejściem, metodologią i zastosowaniem.
Podejście optymalizacyjne:
NSGA-II to algorytm ewolucyjny, który generuje zbiór rozwiązań niedominowanych (front Pareto) poprzez iteracyjne ulepszanie populacji chromosomów. Jest to podejście metaheurystyczne, które nie gwarantuje optymalności, ale efektywnie radzi sobie z problemami wielokryterialnymi i dużymi instancjami.
CPLEX wykorzystuje programowanie liniowe mieszane całkowitoliczbowe (MILP), rozwiązując problem metodą branch-and-bound. Zapewnia optymalne rozwiązanie w sensie lexicograficznym (najpierw minimalizacja nadgodzin, potem opóźnień), ale może być kosztowne obliczeniowo dla większych instancji.
Reprezentacja rozwiązania:
W NSGA-II rozwiązanie to chromosom (permutacja zadań), dekodowany
na harmonogram za pomocą funkcji decode_schedule. Chromosom
koduje kolejność operacji, a harmonogram określa czasy rozpoczęcia i
zakończenia.
W CPLEX rozwiązanie to zestaw zmiennych ciągłych
(start, Cmax, Overtime,
T) i binarnych (Y), które bezpośrednio
określają czasy rozpoczęcia i kolejność operacji na maszynach.
Wielokryterialność:
NSGA-II naturalnie wspiera optymalizację wielokryterialną, generując front Pareto z rozwiązaniami oferującymi różne kompromisy między nadgodzinami a opóźnieniami.
CPLEX stosuje minimalizację lexicograficzną, priorytetyzując nadgodziny nad opóźnieniami, co prowadzi do pojedynczego rozwiązania optymalnego w tym sensie.
Złożoność obliczeniowa:
NSGA-II ma złożoność zależną od rozmiaru populacji
(pop_size), liczby generacji (gens) i kosztów
dekodowania chromosomu, co czyni go skalowalnym dla dużych instancji,
choć z potencjalną utratą precyzji.
CPLEX ma złożoność wykładniczą w najgorszym przypadku z powodu
zmiennych binarnych (Y), co może ograniczać jego
stosowalność dla dużych problemów.
Obie metody zostały przetestowane na tej samej instancji problemu z
pięcioma zadaniami, trzema maszynami, zdefiniowanymi czasami
przetwarzania (p), przypisaniami maszyn
(machine), terminami (due) i limitem
dostępności maszyn (cap = 8).
NSGA-II:
Front Pareto: \([(11, 15), (12, 14)]\), co wskazuje na dwa niedominowane rozwiązania oferujące kompromis między nadgodzinami a opóźnieniami.
Najlepszy chromosom: \([2, 3, 4, 3, 0, 1, 1, 4, 3, 4, 0, 0, 1, 2, 2]\), dający nadgodziny = 11 i opóźnienia = 15 (dla wybranego rozwiązania).
Zalety: Generuje wiele rozwiązań, umożliwiając planiście wybór w zależności od priorytetów (np. mniejsze opóźnienia kosztem nadgodzin). Jest szybki i elastyczny.
Wady: Rozwiązania mogą nie być globalnie
optymalne, a jakość zależy od parametrów (np. pop_size =
40, gens = 80).
CPLEX:
Wynik: Suma nadgodzin = 10
(Overtime = [3, 5, 2]), suma opóźnień = 15 (T
= [3, 4, 3, 5, 0]).
Cmax: [15, 13, 10], wskazując maksymalne czasy zakończenia na maszynach.
Zalety: Gwarancja optymalności w sensie lexicograficznym. Precyzyjne określenie czasów rozpoczęcia i harmonogramu.
Wady: Pojedyncze rozwiązanie ogranicza
elastyczność. Może być wolniejszy dla większych instancji. Wymaga
starannego modelowania (np. odpowiedniego bigM).
| Kryterium | NSGA-II | CPLEX |
|---|---|---|
| Suma nadgodzin | 11 lub 12 | 10 |
| Suma opóźnień | 15 lub 14 | 15 |
| Liczba rozwiązań | Wiele (front Pareto) | Pojedyncze |
| Cmax (maszyny) | Zależne od chromosomu | [15, 13, 10] |
| Optymalność | Przybliżona (metaheurystyka) | Globalna (lexicograficzna) |
| Elastyczność | Wysoka (wybór z frontu Pareto) | Niska (jedno rozwiązanie) |
| Złożoność | Skalowalna | Wykładnicza dla dużych instancji |
Jakość rozwiązań: CPLEX osiąga nieco lepsze nadgodziny (10) w porównaniu do NSGA-II (11 lub 12), co wynika z lexicograficznej minimalizacji, która priorytetyzuje nadgodziny. Jednak suma opóźnień jest porównywalna (15 dla CPLEX i 14 lub 15 dla NSGA-II). NSGA-II oferuje dodatkową elastyczność dzięki frontowi Pareto, umożliwiając wybór rozwiązania z mniejszymi opóźnieniami (14) kosztem nadgodzin (12).
Zastosowanie praktyczne: NSGA-II jest bardziej odpowiedni w sytuacjach, gdzie planista potrzebuje wielu opcji do wyboru, szczególnie w dynamicznych środowiskach produkcyjnych, gdzie priorytety mogą się zmieniać. CPLEX jest preferowany, gdy kluczowa jest precyzja i optymalność dla małej instancji, a priorytetem są minimalne nadgodziny.
Wydajność obliczeniowa: NSGA-II jest szybszy i bardziej skalowalny dla większych problemów, ponieważ jego złożoność zależy głównie od liczby generacji i rozmiaru populacji. CPLEX może wymagać znacznych zasobów obliczeniowych dla instancji z wieloma zadaniami i maszynami z powodu dużej liczby zmiennych binarnych.
Wizualizacja i interpretacja: NSGA-II dostarcza
wizualizacje frontu Pareto, chromosomów i wykresów Gantta, co ułatwia
analizę kompromisów. CPLEX wymaga dodatkowej obróbki wyników (np.
generowania wykresu Gantta na podstawie macierzy start),
ale zapewnia dokładne czasy rozpoczęcia operacji.
Obie metody są skuteczne w rozwiązywaniu problemu harmonogramowania warsztatowego, ale mają różne mocne strony. NSGA-II oferuje elastyczność i skalowalność, generując zbiór rozwiązań Pareto, co jest cenne w praktycznych zastosowaniach, gdzie różne kompromisy mogą być rozważane. CPLEX zapewnia optymalne rozwiązanie w sensie lexicograficznym, co jest korzystne w przypadkach wymagających precyzji i minimalizacji nadgodzin. Wybór między nimi zależy od specyfiki problemu:
Dla małych instancji i potrzeby optymalnego rozwiązania: CPLEX.
Dla dużych instancji, dynamicznych środowisk lub potrzeby wielu opcji: NSGA-II.
W tej instancji CPLEX osiągnął lepsze nadgodziny (10 vs. 11/12), ale NSGA-II zapewnił porównywalne opóźnienia (14 lub 15 vs. 15) i większą elastyczność. Połączenie obu metod – np. użycie CPLEX do małych instancji i NSGA-II do wstępnej analizy dużych problemów – może być efektywną strategią w praktyce produkcyjnej.
Shuangyuan Shi and Hegen Xiong. Solving the multi-objective job shop scheduling problems with overtime consideration by an enhanced NSGA-II. Computers & Industrial Engineering, 2023. Wuhan University of Science and Technology, Wuhan, China; Hubei Engineering University, Xiaogan, China. Available at: https://www.sciencedirect.com/science/article/pii/S0360835224001220.
IBM. Mixed integer-linear programming — IBM Documentation. IBM Knowledge Center, 2023. Available at: https://www.ibm.com/docs/en/icos/22.1.2?topic=opl-mixed-integer-linear-programming-blending-problem.